Evaluating Open-Weight LLMs as Scientific Replication Judges
Benchmarked DeepSeek-R1-Distill models as rubric-based judges on 8,316 PaperBench rubrics. Diagnosed failure modes in schema compliance, hallucination, and seed instability.
Read paper →The project started as an attempt to build a fully open-source autonomous paper-replication loop — an open-weight agent generating code, a syntactic verifier, and an open-weight judge providing feedback for iterative improvement. A quick sanity check on the judge showed it was the bottleneck: without a stable evaluation signal, nothing downstream could improve. We pivoted to diagnosing the judge directly.
Evaluation setup
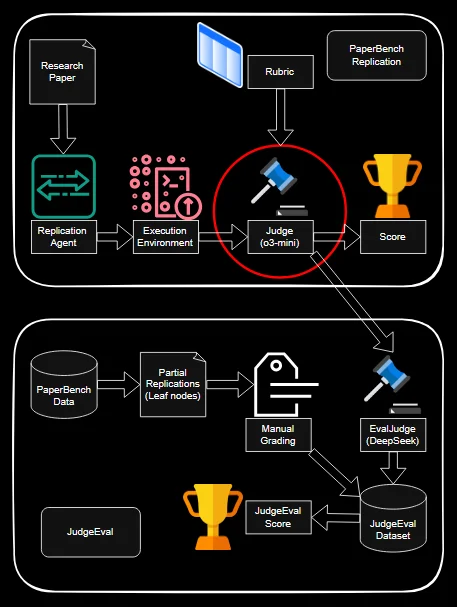
PaperBench is the benchmark: 20 ICML 2024 Spotlight/Oral papers, each decomposed into a hierarchical rubric with 8,316 binary leaf nodes across three categories — Code Development (structural verification), Code Execution (log and output analysis), and Result Analysis (numerical metric comparison). The judge reads rubric text plus workspace evidence (code, logs, metrics) and emits a binary pass/fail. PaperBench’s default judge is o3-mini paired with the SimpleJudge scaffold; I replaced it with four DeepSeek-R1-Distill variants (Qwen-7B/14B/32B and Llama-70B) and scored against the GPT-4 baseline. The 70B model was too slow for the full 20-paper sweep and was evaluated in a reduced single-paper, multi-seed setting.
Two failure axes: coverage and accuracy
A large share of open-weight outputs couldn’t even be parsed. We therefore tracked two quantities separately: accuracy conditional on a parseable output, and sample count (how often the model produced a parseable output at all). Conditional accuracy on Code Execution and Result Analysis was moderate (14B / 32B hit 0.68 / 0.62 on Execution, 0.82 / 0.75 on Result Analysis), but sample counts were small fractions of the rubric space. The 7B’s apparent 0.94 on Code Development was a red herring — only 18 of hundreds of rubric items survived parsing.
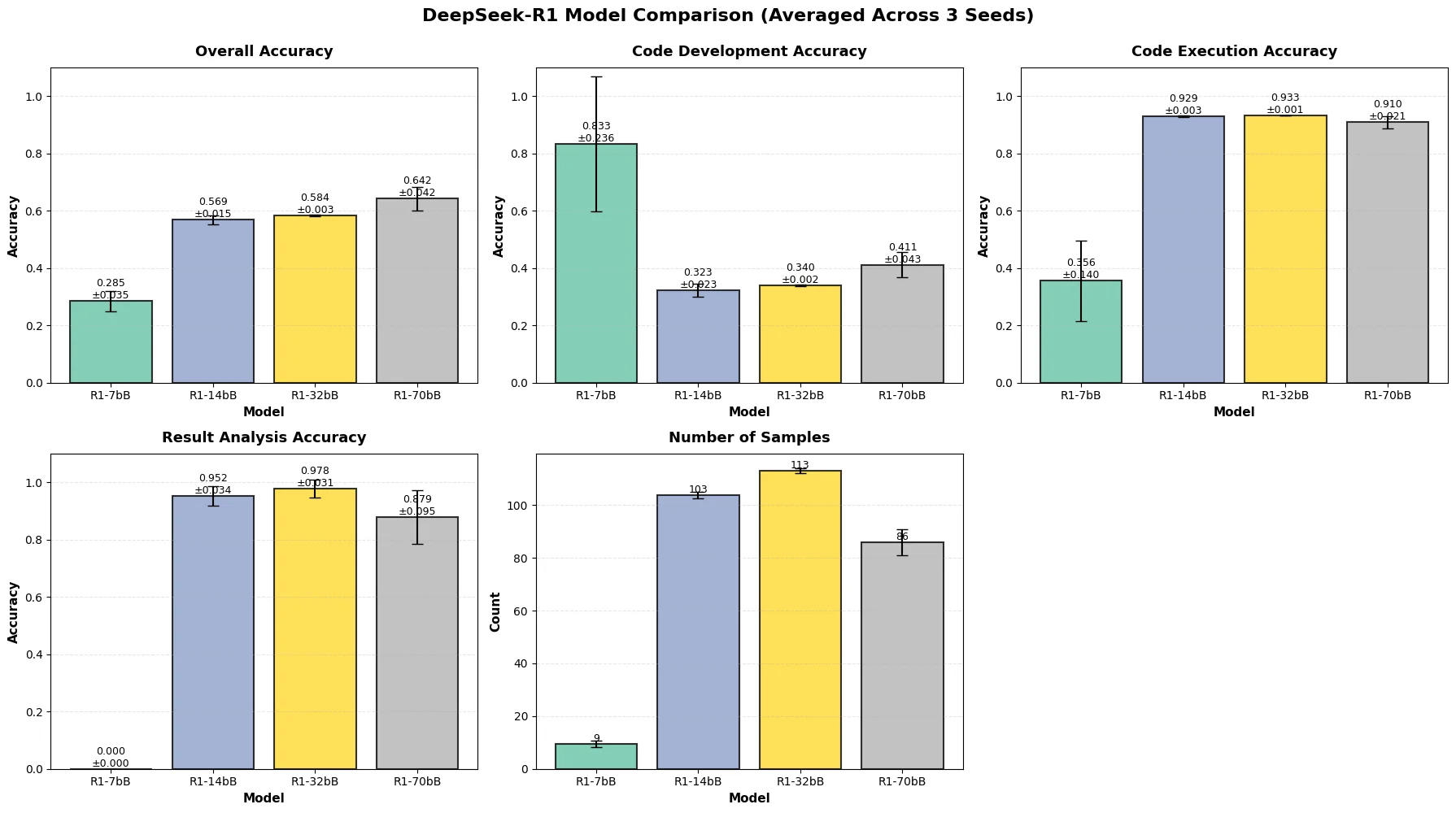
The single-paper study sharpens the coverage story: even the 32B model parses only ~113 rubric items per seed, the 70B drops to ~86, and the 7B bottoms out at 9. Result Analysis accuracy is high when it answers (~0.95 for 14B/32B) but the 7B’s score is 0 because it never produces a parseable Result Analysis judgment at all.
Failure modes
Most coverage loss happens at the output-format stage — models emit free-form prose, partial JSON, or schema-conformant openings that devolve into uncontrolled commentary until the context window runs out. Beyond formatting, semantic failures appeared: for Code Development rubrics, models hallucinated functions and classes that weren’t in the workspace, apparently conditioning on the paper’s described implementation rather than the actual files. For Execution and Result Analysis, judges occasionally missed explicit error messages in logs or labeled failed runs as successful.
Two inference-time ablations were tried: lowering temperature from 1.0 to 0.6 (shortened outputs slightly, coverage unchanged) and moving formatting instructions from system to user role per DeepSeek’s own recommendations (made adherence worse, reverted). Light-touch prompt tweaks weren’t enough — the findings point toward rubric-conditioned fine-tuning, output validation layers, or verifier-augmented pipelines as the real path forward.